1. Représenter c'est choisir...
1.1. Cours

1.2. Compréhension
Représenter et manipuler
Les traitements possibles dépendent fortement des choix de représentation
- Vrai
- Faux
Quelles données ?
La représentation numérique d'un livre peut inclure des données qui ne se limitent pas au contenu textuel. Donnez quelques exemples.
De la variété ?
Il n'existe qu'une seule façon de représenter numériquement un livre.
- Vrai
- Faux
Comment choisir ?
Donnez des exemples de critères qui peuvent gouverner le choix d'une représentation numérique.
Qui choisit ?
Les choix de représentations sont faits par
- Les informaticiens
- Les experts métier
- Les deux
1.3. Activité
Une tâche complexe
Représenter et normaliser est une tâche complexe : l'exemple de HTML. En vous rendant sur les pages wikipedia de HTML et du W3C . Répondez aux questions suivantes :
-
Quelle est l'origine de
HTML? -
Qui développe et publie les spécifications
HTMLdepuis 1995 ? -
Quelle est la version la plus récente de
HTMLet son année de parution ? -
Qui participe au développement du standard
HTMLauW3C? - Quelles sont les étapes pour arriver à être une recommandation ?
-
Qui est responsable du standard
csspour les feuilles de style ?
2. Analyse d'un document : plusieurs vues complémentaires
2.1. Cours
2.2. Compréhension
Vrai ou Faux : vue séquentielle
Avec la vue séquentielle, on peut remplacer les occurrences d'un mot par un autre mot.
- Vrai
- Faux
Vrai ou Faux : vue structurée
Avec la vue structurée, on peut créer une table des matières automatiquement
- Vrai
- Faux
Vrai ou Faux : vue présentation
Un contenu avec une structure a une seule présentation possible
- Vrai
- Faux
La vue qualifiée
Donnez au minimum 4 métadonnées que vous pouvez associer à un livre
Éditeur de textes
Parmi les fonctionnalités suivantes, lesquelles sont possibles ?
- copier/couper/coller
- rechercher et remplacer
- avancer de mots en mots
- corriger l'orthographe
- mettre en gras
Le jardin zen
Pour illustrer à la fois la pertinence de séparer les informations de présentation des autres informations textuelles, mais aussi l'effort de la communauté dans cette direction notamment avec les feuilles de style (CSS ou de documents de traitement de textes). Regardez ces différents liens sur le site la beauté des CSS :
- http://www.csszengarden.com/tr/francais/
- http://www.csszengarden.com/tr/fr/221/
- http://www.csszengarden.com/tr/fr/219/
Entre ces différents designs, qu'est-ce qui change ?
- La structure
- Le contenu
- La présentation
2.3. Activité
Installer LibreOffice
Les activités seront proposées avec le traitement de textes
LibreOffice
. Vous pouvez l'installer depuis le site
http://fr.libreoffice.org/
.
Rappelez-vous que vous devez installer des logiciels depuis les sites officiels uniquement.
Les activités peuvent aussi être réalisées depuis les salles d'accès libre de l'université où tous les logiciels nécessaires sont disponibles.
La structure d'un document texte odt
La structure d'un document texte odt
Téléchargez le
document odt
sur votre machine. Notez bien l'emplacement où vous l'enregistrez. Lancer
LibreOffice
puis ouvrir le document. Pour explorer sa structure :
-
Ouvrez le
navigateur de
LibreOffice(touche F5). Ici, le mot navigateur ne désigne pas un navigateur Web mais une fonctionnalité fournie parLibreOfficepour naviguer dans la structure du document. - Dépliez tous les niveaux de titre pour faire apparaître la structure complète des titres du document.
- Rendre une capture de cette fenêtre de navigateur.
-
Réorganisez la structure : avec le document, déplacez la partie 4.2 en la plaçant juste après la partie 2.2. Pour cela, n'utilisez pas de copier coller mais uniquement les fonctionnalités offertes par l'usage du
navigateur
(touche
F5). - Rendre une capture d'écran de la structure obtenue visible dans le navigateur .
-
Mettez à jour la
table des matières
qui se trouve en début de document :
clic-droitdans la partie grisée de la table des matières et sélectionnerActualiser l'index.
La vue qualifiée d'un document texte odt
Ouvrir le document
document odt
dans
LibreOffice
. Recherchez dans les menus comment trouver les propriétés suivantes :
- le titre,
- le sujet,
- les mots clef,
- la date de création.
Faites une capture d'écran de la fenêtre où vous avez trouvé ces métadonnées.
Un document peut être réduit à des métadonnées
C'est le cas des notices bibliographiques des bibliothèques dont la plus grande partie des fonds n'est pas numérisée. Par conséquent, le contenu des livres n'est pas représenté numériquement et chaque ouvrage est défini par des métadonnées regroupées dans une notice. Nous prenons en exemple le Catalogue des bibliothèques du SCD de Lille 3 .
-
Faites une requête comme, par exemple,
représentation information - Parcourez une ou plusieurs notices des ouvrages en réponse
-
Examinez le contenu de
Sujetset donnez le rôle de ces métadonnées - Indiquez sur quels critères vous pouvez effectuer une recherche.
La structure d'une page web
La structure arborescente est encore plus présente dans les documents au format
HTML
. Les balises sont imbriquées les unes dans les autres et l'ensemble peut être représenté par un arbre. Pour observer cela :
-
Lancer
Firefox, rendez-vous sur la page exemple . -
Pressez les touches
CTRL-MAJ-C(alt-cmd-Csur les Mac). La fenêtre de l'inspecteur de codeHTMLs'ouvre. -
Dans cette fenêtre, observez la structure du document
HTML. Cliquez sur les petites flèches pour découvrir ou cacher les parties de codeHTMLincluses les unes dans les autres. - Sur quelles petites flèches devez-vous cliquer pour arriver au texte Vous pouvez changer la taille... ?
-
La liste des balises associées à chacune de ces petites flèches apparaît dans la zone située juste au dessus du code
HTML. Par exemple,html>body>section>p. Elle représente le chemin dans l'arbre associé au document, depuis sa racine jusqu'au texte sélectionné. Sur l'exemple, un paragraphe dans une section dans le corps du documentHTML.
Quel est le chemin pour arriver au texte Vous pouvez changer la taille... ?
2.4. Activité avancée
Mise en forme et structure
Téléchargez les deux fichiers suivants :
Ouvrez et parcourez ces deux fichiers. Sont-ils identiques ? Qu'est-ce qui les différencie ? Illustrez votre propos en citant des opérations qui seraient plus facilement réalisables avec l'un plutôt qu'avec l'autre et pourquoi.
Réutilisation de styles
Vous avez manipulé jusqu'ici
- representation.odt , un document structuré utilisant les styles par défaut, toutes les opérations liées à la structure du document sont donc accessibles (cf activité structure d'un document texte ), mais la mise en forme est très basique.
- representation1.odt qui est lui aussi structuré et dont les styles des différents niveaux de paragraphe ont été modifiés (taille, typo, couleur, alignement, etc).
Nous allons maintenant réutiliser les styles définis dans representation1.odt pour modifier la présentation sans modifier la structure de representation.odt . Il existe différentes méthodes pour effectuer cela.
Le principe repose sur le fait que les 2 documents utilisent les mêmes noms de styles (les styles par défaut) à savoir :
-
Titre, pour le titre principal du document -
sous-titre, pour le sous-titre -
Titre 1, pour les titres de premier niveau -
Titre 2, pour les titres de deuxième niveau -
corps de texte, pour tous les paragraphes standards
Il s'agit donc de demander à
LibreOffice
d'aller chercher les paramètres de présentation de ces différents styles tels qu'ils sont définis dans le document
representation1.odt
. Cela s'effectue en quelques clics ...
À vous de faire cette manipulation très simple. Cherchez dans l'interface de
LibreOffice
comment effectuer cette opération. Si vous rencontrez des difficultés, n'hésitez pas à aller dans les salles d'accès libre où la dernière version de
LibreOffice
est installée et où des moniteurs peuvent vous aider.
Pensez aussi à utiliser le forum du cours pour poster vos questions ou vos remarques et vous aider mutuellement.
Générer une table des matières
Comme vous avez pu le constater, representation1.odt est structuré et il possède une mise en forme des styles, mais la table des matières n'a pas été créée. Vous allez donc la créer maintenant. Les styles des titres ont été paramétrés pour correspondre à des niveaux différents dans la structure arborescente du document. La génération de la table des matières peut donc se faire en 3 clics ...
-
Cherchez dans les menus de
LibreOfficecomment insérer une table des matières automatiquement. - Faites une capture d'écran montrant la table des matières que vous avez créée.
Numéroter les paragraphes
Nous allons pour finir utiliser une fonctionnalité qui utilise encore la structure arborescente (avec des niveaux imbriqués) du document. Il s'agit de la numérotation automatique des paragraphes. Chacun des titres (Titre 1 ou Titre 2) correspondant à un niveau, le traitement de texte peut facilement les retrouver et calculer les numéros. Ainsi, à chaque nouvelle partie (Titre 1), la numérotation des sous-parties (Titre 2) recommence à 1.
Chercher dans
LibreOffice
comment numéroter automatiquement les parties en utilsant la notation suivante :
A / REPRÉSENTER C’EST CHOISIR…
B / ANALYSE D'UN DOCUMENT,
PLUSIEURS VUES COMPLÉMENTAIRES
1 - Introduction
2 - Le Contenu, Une Vue Séquentielle
etc.
3. Documents numériques - formats et normes
3.1. Cours




3.2. Compréhension
Extensions de fichier
Dans le nom de fichier
mondocument.txt
, quelle est l'extension ?
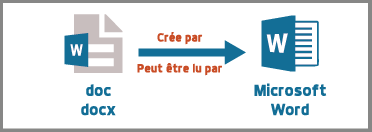
Éditeur de textes et fichier doc
Avec un éditeur de textes, je peux ouvrir un fichier doc
- Vrai
- Faux
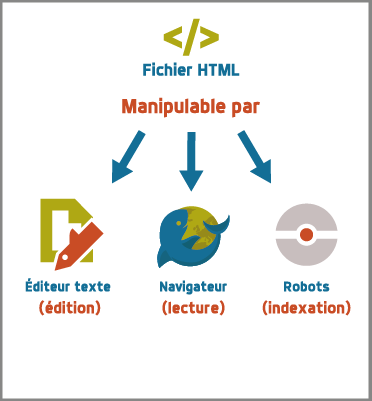
Éditeur de textes et HTML
Avec un éditeur de textes, je peux ouvrir un fichier HTML
- Vrai
- Faux
Contenu et présentation
Un contenu avec une structure a une seule présentation possible
- Vrai
- Faux
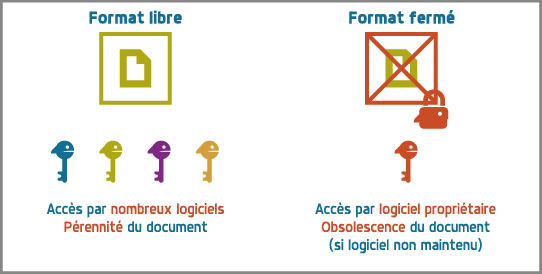
Conversions de formats
Est-il toujours possible de convertir un document d'un format vers un autre format ?
- Vrai
- Faux
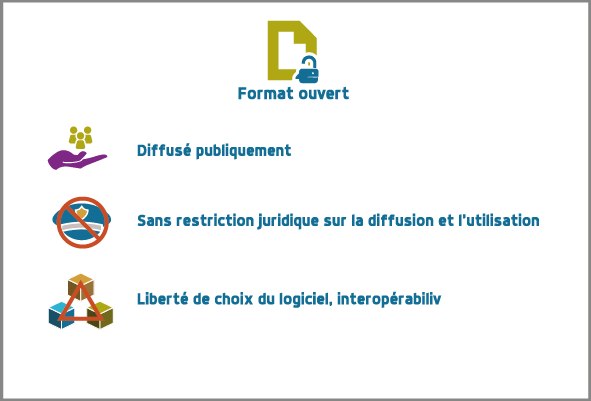
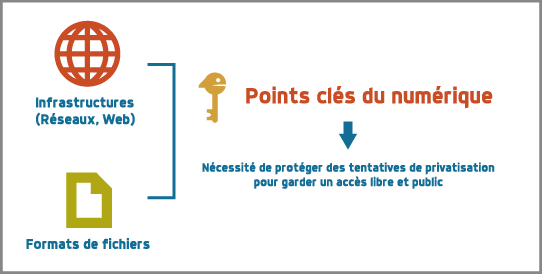
Format ouvert et interopérabilité
Un format ouvert facilite l' interopérabilité
- Vrai
- Faux
3.3. Activité
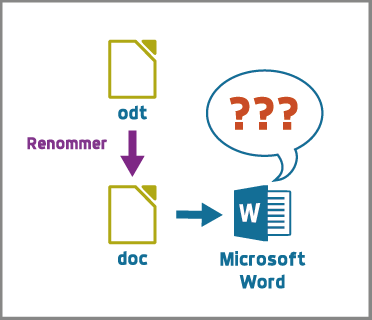
Format .doc
Lisez la page Wikipedia suivante sur le format doc et cochez les réponses vraies.
- Les fichiers avec l'extension doc désignent une chose unique.
- Ce format est ouvert.
- Ce format est toujours développé ?
- Ce format a été étendu.
Format PDF
Lisez la page Wikipedia sur le format pdf et répondez aux questions suivantes
- Est-ce un format ouvert ?
-
Peut-on lire et écrire du
pdfavec des logiciels différents ? - Que signifie portable ?
- Les documents dans ce format peuvent-ils toujours être reconstitués à l'identique ? Pourquoi ?
4. Documents numériques textuels
4.1. Cours
4.2. Compréhension
Unicode def
Qu'est-ce que Unicode ?
- une manière standardisée de dessiner des caractères d'une langue.
- un standard qui attribue à chaque caractère dans de nombreuses langues, un nom et un numéro.
Point de codage
Quel est le point de codage Unicode du point d'exclamation (!) et son nom ?
Caractère informatique, caractère et glyphe
En informatique le caractère est un peu différent du caractère en typographie...
- Le caractère informatique est une notion abstraite pour désigner un symbole d'écriture.
- Le caractère informatique peut être invisible.
- Le caractère typographique ou glyphe est le dessin imprimé ou reproduit à l'écran.
- Le caractère informatique est une émoticône qui permet de représenter un sentiment.
Caractères sans glyphe
Donner des exemples de caractères non imprimables
4.3. Activité
Autres codes -- Un code mécanisé
- Que permettait de représenter le code Baudot ?
- Pourquoi aujourd'hui ce code Baudot n'est plus utilisé pour représenter les caractères?
Autres codes -- un code par le signal
- Que permet de représenter le code Morse
- Ce code est basé sur des impulsions et des silences. Quels sont-ils ?
-
Trouver pour quelle raison la lettre
Ea le plus court codage ?
Unicode actu
Rendez vous sur le site Unicode .
- Allez dans le menu Proposed Changes -- Proposed Characters . Vous y verrez des caractères en attente d'intégration dans le standard.
- Allez dans le menu The Consortium -- Who we are . Constatez la diversité du consortium et de son organisation.
- Regardez les caractères actuels .
- Regardez en particulier Basic Latin qui ont été les premiers caractères codés en informatique dans une table 'ASCII`.
Codage des caractères dans les pages Web
Les caractères sont représentés conformément au standard
Unicode
et au codage
UTF-8
pour 80% des pages Web.
- Ouvrez la page suivante puis ensuite cette autre page
- Que constatez-vous ?
-
Consultez les codes sources de ces deux pages (utilisez la séquence de touches
CTRL-Uoucmd-Usur Mac pour l'obtenir) et voyez la différence. Recopiez la ligne qui déclare cet encodage du jeu de caractères.
Structure implicite
Ouvrir le fichier suivant avec un éditeur de texte. Modifiez la taille de la fenêtre de l'éditeur en l'agrandissant ou la réduisant. Quelles observations vous permettent de vérifier que le paragraphe est bien un élément de structure et que la ligne n'est pas un élément de structure ?
Compter les mots
On considère le texte suivant :
Bonjour l'ami. Soyez curieux bien-sûr ; essayez-donc ! Signé : marc.latour@yahoo.com
- Comptez le nombre de mots.
- Saisissez le texte dans LibreOffice et, dans le bas de la fenêtre le logiciel de traitement de textes vous indique le nombre de mots du document ou d'une sélection. Qu'observez-vous pour le texte et pour les parties de textes quant au nombre de mots ? Est-ce le résultat auquel vous vous attendiez ?
- Effectuez la même opération dans un éditeur de textes et posez vous les mêmes questions. Vous chercherez dans les différents menus comment obtenir les statistiques du texte qui indiquent le nombre de mots.
4.4. Activité avancée
Les paragraphes, structure explicite
Dans un traitement de textes, la notion de paragraphe est explicite. Il existe un caractère informatique signifiant fin de paragraphe et l'utilisateur l'insère explicitement dans un texte en appuyant sur la touche
Entrée
. L'appui sur la combinaison
MAJ-Entrée
insère elle une fin de ligne, mais sans pour autant changer de paragraphe. À vous de constater cela dans votre traitement de textes :
- Dans un nouveau document saisissez un très long texte. N'utilisez qu'une seule fois la touche entrée pour signifier que ce long texte est composé de deux paragraphes.
- Dans les options de mise en forme des paragraphes centrez le premier. Vérifiez que le second n'est pas centré.
-
Au milieu du second, appuyez sur
MAJ-Entréepour retourner à la ligne. Dans les options de mise en forme des paragraphes alignez le second paragraphe à droite. Vérifiez que la mise en forme s'applique, y compris après le retour à la ligne.
codage des points de codage -- UTF-8 et UTF-16
Le standard Unicode associe à tout caractère pris en charge par Unicode un nom et un numéro appelé son point de codage. Ce point de codage est un nombre entier qu'il faut encore coder en langage machine, c'est-à-dire avec les seuls symboles 0 et 1 qu'on regroupe dans des suites de huit symboles appelés octets. Rendez vous sur la page wikipedia UTF-8 . Lisez le texte en répondant aux questions suivantes :
-
Combien peut-on coder de caractères avec
UTF-8? - Est-ce que tous les caractères sont codées sur le même nombre d'octets ?
- Le A a pour nom "LatinCapital Letter A" et pour point de codage 65. Sur combien d'octets est-il codé ? Donner son code binaire.
- Quels sont les caractères codés sur 1 octet ?
- Donnez des caractères usuels en écriture française qui ne sont pas codés sur un seul octet
- Si un octet commence par 0, on peut dire que cet octet code un caractère. Si un octet commence par 110, combien faut-il prendre d'octets ? Avec 1110 ? Avec 11110 ?
Exemple de html
HTML Le HTML est un langage très simple à apprendre. Vous pouvez réaliser quelques essais mineurs avec cet exercice. Respectez bien l'imbrication des balises pour que l'ensemble forme bien un bon arbre. Pour aller plus loin, suivez les cours d'option informatique métiers du web ou lisez les nombreux tutoriels sur internet.
- Ouvrez le fichier html.html .
- Essayez d'ajouter un paragraphe, un titre de niveau 2.
-
Pour les plus aguerris ajoutez une liste avec les balises
<ul><li>élément</li></ul>.
Markdown
Markdown
Un autre langage de description de texte est particulièrement utilisé, il s'agit de
Markdown
. Pour information, le cours que vous suivez a été entièrement rédigé avec cette syntaxe. Nous vous proposons de le découvrir en passant par un site qui permet d'écrire du texte en
markdown
et qui en propose un rendu en html ou des exports dans différents formats. Ouvrez le fichier
markdown.html
.
En observant cet exemple, trouvez
comment en
Markdown` :
- mettre des mots en italique ?
- mettre des mots en gras ?
- définir un titre de premier niveau ?
- de deuxième niveau ?
- faire une liste à puces ?
- mettre tout un paragraphe en exergue comme une citation?
- délimiter des paragraphes ?
LaTeX
Enfin, le format de représentation numérique de documents scientifiques, qui permet de générer de textes de très grande qualité typographique est LaTeX. (Voyez par exemple le site arXiv et les formats de soumission d'articles autorisés ). Ici encore, c'est un langage structuré et on peut le comprendre de cette façon. À titre d'exemple, regardez le document suivant avec un éditeur de textes (bloc-note, textEdit, gedit, selon votre ordinateur) ainsi que son rendu en PDF .
Quelles commandes permettent de structurer les parties de document ?
Règles de typographie
Lorsque vous utilisez un logiciel comme
LateX
, vous spécifiez la structure du document et certains éléments de mise en forme. C'est le programme qui respecte les règles de l'édition scientifique pour générer le document imprimable : taille des espaces, sauts de ligne, césure des mots, sauts de page, placement des figures, ... Cependant, il reste à votre charge de connaître et respecter certaines régles typographiques minimales comme espace après la virgule, espace avant et après le point-virgule (seulement après en anglais). Voici un document sur les
bonnes pratiques de typographie
.
5. Les images
5.1. Cours
5.2. Compréhension
Quelle représentation ?
Vectorielle ou matricielle Je veux représenter une carte routière. Je dispose des relevés des positions des routes, des bâtiments principaux, des délimitations des surfaces des villes et villages. Quelle représentation vous semble la plus adaptée?
- Une image vectorielle
- Une image matricielle
Une capture d'écran
Je réalise une capture d'écran. À votre avis l'image générée est plutôt :
- une image matricielle.
- une image vectorielle
5.3. Activité
Échantillonner les images
Plusieurs appareils photo sont équipés d'une cellule qui permet de capturer les image sur une grille de 4000 par 3000. Dans les notices, il est indiqué alors combien de mégapixels (millions de pixels) ?
La qualité de l'image
Qualité et résolution La qualité d'une image imprimée va dépendre du nombre de pixels, mais aussi de la taille de ces pixels. Vous avez sans doute remarqué que la qualité d'un agrandissement photo peut être parfois dégradé par rapport à un original de taille plus réduite. Des unités mesurent cette finesse des images, appelée encore la résolution. Cherchez sur internet les unités utilisées pour indiquer la résolution des images.
Aide : l'influence anglo-saxonne est bien présente, le pouce (inch) est utilisé.
Échantillonner la musique
Un CD contient une représentation numérique standardisée de la musique. Dans ce cas, on prend une mesure de la valeur du son plusieurs milliers de fois par seconde. Les milliers de fois par seconde se disent kilo hertz (Khz). Quelle est la valeur de l'échantillonnage utilisée dans le format des CD audio ?
Les valeurs de Rouge de Vert ou de Bleu
Pour chaque pixel, échantillon spacial de l'image, une valeur de couleur est mémorisée. La qualité de l'image dépend à la fois du nombre et la taille des pixels, mais également de la précision de cette mesure de couleur. Très souvent, chaque proportion de rouge, vert et bleu est stockée chacune sur un octet. Mais combien de valeurs possibles peut-on représenter avec un octet ?
Les valeurs RVB
Avec 1 octet par couleur primaire :
- combien d'octets sont nécessaires pour coder une couleur dans le système RVB (Rouge Vert Bleu)
- Combien de couleurs différentes peuvent être codées ?
Pierre Bézier
- Qui est Pierre Bézier ?
- Qu'a-t-il inventé ?
Courbe de Bézier
Il est possible de définir des courbes avec peu d'informations. Par exemple, une courbe de Bézier cubique est définie par la donnée de 4 points A, B, C et D.
- A est le point de départ,
- AB donne la direction initiale,
- D est le point d'arrivée et
- CD donne la direction d'arrivée et le reste ce sont des mathématiques. Notez que B et C donnent des directions et que la courbe ne passe pas par B et C.
Vous pouvez voir des animations de construction de courbe sur la page courbe de Bézier et lire la section Applications de cette page.
5.4. Activité avancée
métadonnées de photos
La plupart des appareils photos numériques ajoutent des métadonnées à chaque prise de vue. Des standards comme EXIF ou IPTC existent pour les représenter. Recherchez des exemples de métadonnées associées aux photos.
manipulations images SVG
Vous pouvez vous initier à la définition d'images vectorielles avec le standard
SVG
avec
cette page
. Essayez donc de changer l'épaisseur de la ligne rouge, la position du rectangle bleu, le rayon du cercle jaune. Et si vous êtes forts ajoutez une nouvelle ligne verte horizontale!
Les images CMJN
Un autre modèle de couleur est utilisé dans le monde de l'édition, il s'agit du modèle
CMJN
. Le principe est similaire au modèle RVB, il s'agit de décrire une couleur par combinaison de plusieurs couleurs primaires. Mais alors que le RVB correspond aux technologies des écrans, le CMJN est adapté au monde de l'impression.
Que signifient les initiales CMJN ?
6. Ouverture, interopérabilité, licences, ... et liberté
6.1. Cours
6.2. Activité
Les personnages du libre
Qui est Richard Stallman ? Qui est Lawrence Lessig ?
Creative Commons
Quelles sont les différentes variantes de creative commons ?
Le logiciel libre
Quels sont les 4 principes du logiciel libre (voir le site de l'April ) ?
Annexe : réutiliser ce module
Archive IMS CC utilisable dans les LMS Moodle, Claroline, Blackboard, etc: module3.imscc.zip
Archive EDX : module3_edx.tar.gz